Regression Trees
All regression techniques contain a single output (response) variable and one or more input (predictor) variables. The output variable is numerical. The general regression tree building methodology allows input variables to be a mixture of continuous and categorical variables. A decision tree is generated when each decision node in the tree contains a test on some input variable's value. The terminal nodes of the tree contain the predicted output variable values.
A Regression tree may be considered as a variant of decision trees, designed to approximate real-valued functions, instead of being used for classification methods.
Methodology
A regression tree is built through a process known as binary recursive partitioning, which is an iterative process that splits the data into partitions or branches, and then continues splitting each partition into smaller groups as the method moves up each branch.
Initially, all records in the Training Set (pre-classified records that are used to determine the structure of the tree) are grouped into the same partition. The algorithm then begins allocating the data into the first two partitions or branches, using every possible binary split on every field. The algorithm selects the split that minimizes the sum of the squared deviations from the mean in the two separate partitions. This splitting rule is then applied to each of the new branches. This process continues until each node reaches a user-specified minimum node size and becomes a terminal node. (If the sum of squared deviations from the mean in a node is zero, then that node is considered a terminal node even if it has not reached the minimum size.)
Pruning the Tree
Since the tree is grown from the Training Set, a fully developed tree typically suffers from over-fitting (i.e., it is explaining random elements of the Training Set that are not likely to be features of the larger population). This over-fitting results in poor performance on real life data. Therefore, the tree must be pruned using the Validation Set. Analytic Solver Data Science calculates the cost complexity factor at each step during the growth of the tree and decides the number of decision nodes in the pruned tree. The cost complexity factor is the multiplicative factor that is applied to the size of the tree (measured by the number of terminal nodes).
The tree is pruned to minimize the sum of: 1) the output variable variance in the validation data, taken one terminal node at a time; and 2) the product of the cost complexity factor and the number of terminal nodes. If the cost complexity factor is specified as zero, then pruning is simply finding the tree that performs best on validation data in terms of total terminal node variance. Larger values of the cost complexity factor result in smaller trees. Pruning is performed on a last-in first-out basis, meaning the last grown node is the first to be subject to elimination.
Ensemble Methods
Analytic Solver Data Science offers three powerful ensemble methods for use with Regression trees: bagging (bootstrap aggregating), boosting, and random trees. The Regression Tree Algorithm can be used to find one model that results in good predictions for the new data. We can view the statistics and confusion matrices of the current predictor to see if our model is a good fit to the data; but how would we know if there is a better predictor just waiting to be found? The answer is that we do not know if a better predictor exists. However, ensemble methods allow us to combine multiple weak regression tree models, which when taken together form a new, accurate, strong regression tree model. These methods work by creating multiple diverse regression models, by taking different samples of the original data set, and then combining their outputs. (Outputs may be combined by several techniques for example, majority vote for classification and averaging for regression) This combination of models effectively reduces the variance in the strong model. The three types of ensemble methods offered in Analytic Solver (bagging, boosting, and random trees) differ on three items: 1) the selection of Training Set for each predictor or weak model; 2) how the weak models are generated; and 3) how the outputs are combined. In all three methods, each weak model is trained on the entire Training Set to become proficient in some portion of the data set.
Bagging (bootstrap aggregating) was one of the first ensemble algorithms ever to be written. It is a simple algorithm, yet very effective. Bagging generates several Training Sets by using random sampling with replacement (bootstrap sampling), applies the regression tree algorithm to each data set, then takes the average amongst the models to calculate the predictions for the new data. The biggest advantage of bagging is the relative ease that the algorithm can be parallelized, which makes it a better selection for very large data sets.
Boosting builds a strong model by successively training models to concentrate on records receiving inaccurate predicted values in previous models. Once completed, all predictors are combined by a weighted majority vote. Analytic Solver Data Science offers three variations of boosting as implemented by the AdaBoost algorithm (one of the most popular ensemble algorithms in use today): M1 (Freund), M1 (Breiman), and SAMME (Stagewise Additive Modeling using a Multi-class Exponential).
Adaboost.M1 first assigns a weight (wb(i)) to each record or observation. This weight is originally set to 1/n, and will be updated on each iteration of the algorithm. An original regression tree is created using this first Training Set (Tb) and an error is calculated as
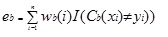
where, the I() function returns 1 if true and 0 if not.
The error of the regression tree in the bth iteration is used to calculate the constant ?b. This constant is used to update the weight (wb(i). In AdaBoost.M1 (Freund), the constant is calculated as
αb= ln((1-eb)/eb)
In AdaBoost.M1 (Breiman), the constant is calculated as
αb= 1/2ln((1-eb)/eb)
In SAMME, the constant is calculated as
αb= 1/2ln((1-eb)/eb + ln(k-1) where k is the number of classes
where, the number of categories is equal to 2, SAMME behaves the same as AdaBoost Breiman.
In any of the three implementations (Freund, Breiman, or SAMME), the new weight for the (b + 1)th iteration will be
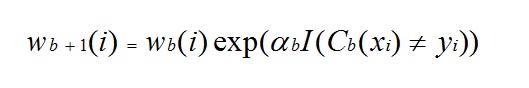
Afterwards, the weights are all readjusted to the sum of 1. As a result, the weights assigned to the observations that were assigned inaccurate predicted values are increased, and the weights assigned to the observations that were assigned accurate predicted values are decreased. This adjustment forces the next regression model to put more emphasis on the records that were assigned inaccurate predictions. (This ? constant is also used in the final calculation, which will give the regression model with the lowest error more influence.) This process repeats until b = Number of weak learners. The algorithm then computes the weighted average among all weak learners and assigns that value to the record. Boosting generally yields better models than bagging; however, it does have a disadvantage as it is not parallelizable. As a result, if the number of weak learners is large, boosting would not be suitable.
The random trees method (random forests) is a variation of bagging. This method works by training multiple weak regression trees using a fixed number of randomly selected features (sqrt[number of features] for classification and number of features/3 for prediction), then takes the average value for the weak learners and assigns that value to the strong predictor. Typically, the number of weak trees generated could range from several hundred to several thousand depending on the size and difficulty of the training set. Random trees are parallelizable, since they are a variant of bagging. However, since tandom trees selects a limited amount of features in each iteration, the performance of random trees is faster than bagging.
Regression Tree Ensemble methods are very powerful methods, and typically result in better performance than a single tree. This feature provides more accurate prediction models, and should be considered over the single tree method.